|
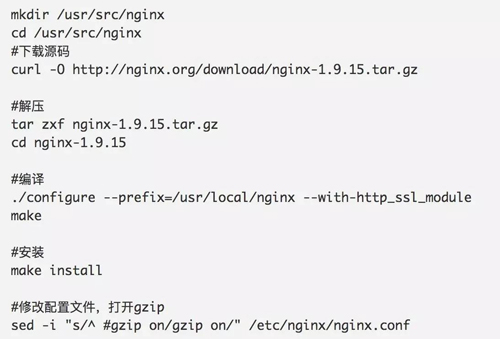
关于题目“云计算时代的自动化运维”,用通俗的话讲,就是应用的自动化部署。 第一个关键词是自动化,自动化代表高效率、低成本;第二个关键词是应用部署。即,不涉及讲物理基础设施的运维(如机房基建、能源、消防、安保、布线等等)。 假设一个企业要做一个电商网站,典型的运维流程是这样: 1. 购买硬件设备:服务器、交换机。可能还有路由器、负载均衡器、防火墙,不一一穷举了。 2. 在服务器上安装操作系统 3. 在服务器上安装配置基础环境(数据库、Web服务器、搜索引擎等) 4. 在服务器上安装配置应用软件(用Java、PHP开发的电商软件) 5. 把硬件设备送进机房托管,开通公网访问 6. 监控运维中的业务,并做日常备份、扩容/缩容、迁移、升级 如果是使用公有云,则没有第1,2,5步,直接购买公有云的虚拟机、容器、平台服务(文件存储、关系数据库、内容分发等) 应用环境和应用软件部署是指第3步和第4步。 1 操作系统自动化部署 第2步是物理祼机的部署,现在市面上的主流服务器,都支持IPMI管理,通电接上管理端口就可以完成BIOS设置,再辅以DHCP, TFTP, KickStart可以实现无人值守的自动化安装操作系统。 目前虚拟化、私有云、公有云已经相当普及,除了一些对特殊硬件有要求的场合,和一些历史遗留场合,其它大部分场合都可以用虚拟机,物理机上安装的是宿主操作系统,应用软件装在虚拟机里,这样物理祼机就只需要安装宿主操作系统,需求相对简单,没有应用部署那么复杂。装完之后不会经常去改动,运行稳定。 2 应用部署 与操作系统部署相比,应用部署复杂性高得多,主要表现在: · 场景繁多 一个小型的B2C网站,有负载均衡器、Web服务器、应用服务器、缓存服务器、搜索引擎、分布式文件系统、监制中心、日志中心、VPN服务器等十多种服务器角色 · 依赖复杂 软件包之间有依赖,服务器之间有通信依赖 · 配置各异 除标准的ini,xml, yaml, json, properties文件外,iptables, sysctl, nginx, haproxy, pptpd等都有自己独特的配置文件格式,多达上百种。文档描述和运维脚本编写都有相当大的难度。 3 应用部署技术发展历程 下面以在CentOS上安装nginx为例,回顾一下应用部署技术的发展历程: 3.1 手工安装配置 这是最古老的部署方式,直到今天也被广大小规模团队广泛采用。部署过程往往会产生这样一份文档供日后参考: ![]()
3.1.1 优点 3.1.1.1 灵活性高 可以安装任何想要的版本,启用任何想要的模块(包括自行开发的私有模块) 3.1.1.2 学习门槛低 文档是自然语言写成,阅读和书写都很简单,不需要额外学习其它技术语言。安装配置用到的工具、命令也较少,主要是网络下载、解压缩、编译、文本编辑几种,容易掌握。 3.1.2 缺点 作为最古老的部署技术,缺点也是显而易见的: 3.1.2.1 文档不精确 由于文档是自然语言写的,是写给运维工程师阅读的,而不是给机器执行的。文档写的是什么,跟机器上实际执行的是什么,并不是100%一致的,需要人肉转换。在长期版本变更、人员更替中极容易出现疏漏。当然,可以从行政管理上解决这类隐患。很多大公司都喜欢搞流程,用测试审核流程来督促人少犯错。然而,只要是这个文档是给人看而不是给机器执行的,这个文档就会一直面临笔误、表达不精确、更新不及时等隐患,要用流程来彻底杜绝这些隐患,成本很高。 3.1.2.2 效率低 上述5个步骤都是串行的,必须做完一步才能进行下一步。第1步和第3步是比较耗时的,若网速不快,或者编译时间太长,运维工程师会浪费时间等待。 另一方面,若有多台机器需要执行同样的部署操作,也无法减少重复性操作。 3.2 自动化部署:shell脚本 若服务器稍有规模的团队里,上述手工部署就成了一个大问题。 人肉阅读的文档急需转换成机器执行的代码。最早也最广泛运用的自动化部署技术便是shell脚本。以bash为例,上述5步写成bash shell就像这样(示例代码,未经测试): ![]()
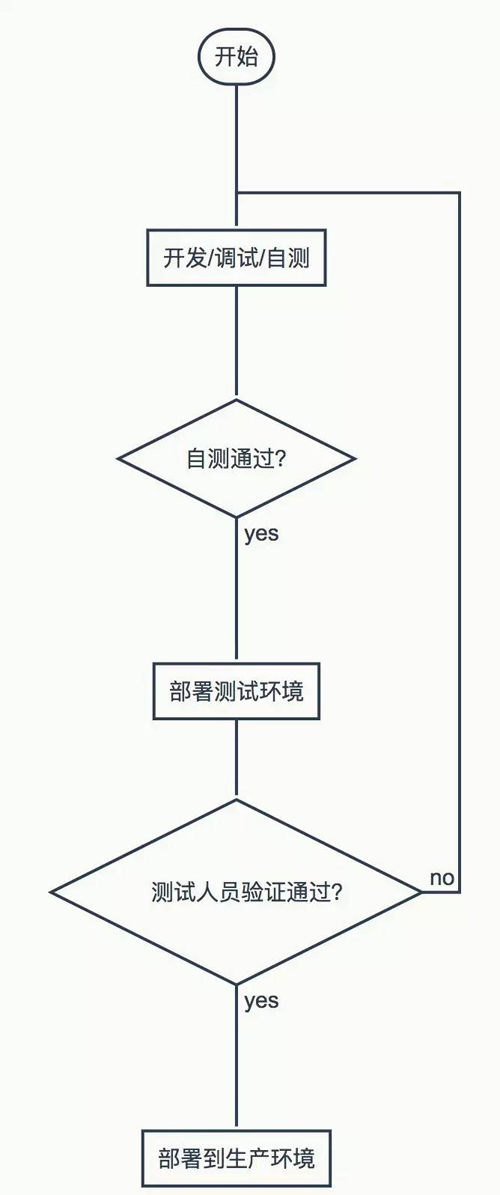
直接运行这个脚本,就可以自动安装配置好nginx了。 相比手工部署,使用shell脚本的缺点只有两点:一是写代码需要一定学习门槛。二是维护的技术难度会略高。 3.2.1 优点 3.2.1.1 精确 由于shell脚本是给机器执行的,shell脚本自身就是一份精确的可执行的文档,所以,不存在笔误、表达不精确、更新不及时的问题。 3.2.1.2 效率高 运维工程师只要把脚本启动起来就可以做别的工作了。 3.2.2 bash的缺点 Bash是几乎所有linux发行版内置的,环境兼容性好,简洁易学。但它却不是运维编程的终极之选。具体来说有两大缺点: 3.2.2.1 缺少高级语言特性 Bash不是一门高级编程语言,和Perl/Python/Ruby/PHP这些同样可以用作shell编程的语言相比,缺少很多高级语言特性,而这些特性在运维部署工作中会用到。 3.2.2.1 工具链不丰富 由于不支持OOP,因此没有完整的单元测试框架。 开发框架、缺陷分析、性能分析工具也几乎是一片空白。IDE支持虽有(JetBrains公司IntelliJ就有bash shell插件),但功能不多。 3.3 自动化部署:运维DSL 得益于虚拟化和公有云的快速普及,高效高质量地完成应用部署不再是大公司专有的需求,也成了某公司的刚需,前面分析过了,bash shell不能胜任大规模的、复杂的应用部署,自动化运维编程语言DSL(Domain Specific Language)被发明出来,puppet, chef,ansible, saltstack是其中杰出的代表。 4 自动化运维技术发展趋势展望 4.1 部署工作代码化 无论是使用bash / python shell,还是使用puppet、chef等DSL,都可以完成代码化这个过程。把手工操作变成代码。 使用代码自动化部署应用环境和应用,才能保证无论在办公室测试环境,还是在机房生产环境,每次运行这个部署代码,都能得到相同的结果。这是一切自动化部署的基础。 4.2 运维代码版本化 运维代码要和Java,PHP等应用代码一样,纳入SVN、GIT代码仓库,执行严格的开发-测试-上线-回滚流程。 这样便可利用svn/git的成熟SCM功能,用于这样一些场景: 4.2.1 新建分支 运维代码由1.0升级到2.0,增加了缓存层。则可以从1.0复制出一个分支出来,命名为2.0,然后再在2.0的基础上修改。 4.2.2 差异比较 若要了解1.0和2.0的运维架构到底发生了什么变化,执行svn和git的diff即可查看每一行代码的变化。 4.2.3 历史归档 1.0版稳定运行了半年,升级到2.0版本,此时1.0版冻结写请求,归档留存。2.0上线运行一段时间,发现稳定性不够。可以从归档中找出1.0版本的部署代码,回滚到1.0版本。 4.3 测试环境高保真 很多公司的测试和生产环境存在操作系统不一致、软件版本不一致、配置项不一致的情况。这种不规范的运维有两大后果:一是bug在测试环境未能测出,导致线上故障;二是线上出现异常时,测试环境不能复现。 一个应用至少有两种环境:测试环境、生产环境。大一点的公司还会分成:开发环境、功能测试环境、性能测试环境、预发环境、生产环境。这么多的环境的自动化部署代码,原则上应该是90%以上都相同,只有少数地方不一样。 4.4 自动化测试 使用代码自动化部署完之后,服务器是否立即可用,需要测试验证。自动化测试能让整个运维过程更加高效。 在应用开发领域,自动化测试、单元测试已经非常普及了,运维开发也可以做一些类似的自动化验收测试工作: 4.4.1 终端应用测试 模拟一个客户端访问刚刚部署好的服务,例如:验证其RESTfulAPI是否得到预期的结果。 优点是,最接近实际用户,若此测试通过,则说明装软件、改配置、启服务各项工作都正确。缺点是,若测试不通过,不能立即定位出哪里出错了。定位问题需借助下面更底层的测试。 4.4.2 四层网络测试 使用nmap之类的工具检测目标端口是否正常响应(包括防火墙是否放行) 4.4.3 本机测试 · 用yum,apt检测包是否安装 · 用service status检测守护进程是否正常支持 · 用ps检测进程是否正在运行 · 用ls检测文件是否存在 · 用grep检查配置荐是否设置成了指定的值 自动化测试用例覆盖足够全面,我们便有可能实现一台机器从祼机到上线服务全部自动化完成,无人值守。若没有自动化测试,应用部署完成之后,仍然需要人工验证是否满足上线服务的要求。 4.5 工作流 运维代码从开发到上线发挥作用,也应该和应用代码一样遵循下面的工作流: ![]()
这个流程图只展示了最基本的要求:部署到生产环境前必须经过测试环境验证。更复杂的还有代码reivew、性能测试环境验证、漏洞扫描环境验证、预发环境验证,生产环境分批发布等环节。 很多公司的现状是运维工程师开两个ssh终端,一条命令,先在本地环境跑一下看看效果,成功就拿到线上去跑了。更有甚者,不经过本地验证直接到线上操作了。这主要是因为运维工作没有充分代码化,运维代码没入svn、git仓库。 4.6 图形化界面和IDE 运维领域一直都缺少通用的、高效的图形界面和IDE。这大约有两个原因: 一是需求不强劲。运维编程的复杂度毕竟比应用编程简单好几个数量级。运维日常工作也没有代码化,还有大量的人工操作,所以,运维代码通常像冰糖葫芦一样,一个个脚本虽然串在一起,但大都是个独立的个体,没有那么强的代码组织结构。 二是运维社区极客氛围浓重。就连应用编程领域也只有Java、.NET等语言的用户比较偏爱IDE。在PHP、Python、Perl社区,vim党、emacs党、sublime text党、notepad++党各领风骚。这些党派崇拜的编辑器不同,但有一个共同信仰:不依赖IDE写代码是一个优秀程序员的必备素质。 关于这个问题,我是这样认为的,有高科技能提升编程生活质量,为什么不用用?即使puppet、chef把运维编程体验做到这么好了,我仍然期待运维业界涌现一批Eclipse、AdobeFlash这样的图形界面、IDE。让IDE的高效易用和运维的命令行操作相得益彰。 4.7 运维代码分治 运维界有一句祖训:没有折腾,就没有故障。 但为了快速响应业务需求和提高资源利用率,运维又不得不频繁折腾。有没有什么办法能打破“折腾越多、故障越多”的魔咒?有,分而治之。 分治,就是把风险高的和风险低的分开、重要性高的和不高的分开、简单的和复杂的分开、频繁变动的和不频繁的分开。应用编程领域,大家积极探索和实践的各种架构、框架、模式,归根到底都在做两件事:封装复杂度、隔离变化。 运维架构层的分治,在业界已经非常普遍了,比如应用服务器和数据库服务器分离、交易数据库和用户数据库分离;生产环境和测试环境隔绝。 4.7.1 配置项和逻辑代码分开 其实业界早就在这么做了,puppet的hiera和saltstack的pillar都是做这个用的。 有些运维变更,可能只改变了配置项的值,而并没改变运维代码里的业务逻辑、流程控制。如果只改配置文件,不改运维脚本。发布风险就低了很多,起码不会导致语法错误。 4.7.2 会变动的配置项独立 就像应用开发领域里的模板引擎一样,把配置文件写成模板,模板中包含变量,运维工具或者运维平台解析模板内容,把变量替换成真实的值。 4.7.3 服务发现 将会变动的配置项独立出来动态维护,还可以实现服务发现。以haproxy + etcd + confd为例: confd就是一个模板引擎,类似Java里有Velocity和Python里的jinja。不同之处是:confd还有自动轮询etcd的能力。使用confd解析和管理haproxy的配置文件,摘录如下: 跟原生的haproxy配置文件不同,最后三行是confd模板。 etcd是一个KV存储,类似memcached,不同之处是etcd生来就是分布式的,自带高可用和负载均衡的基因,同时还有HTTPRESTful API,存取方便。使用etcd存储后端服务器列表。 当后端有一台nginx服务启动的时候,调etcd的api把这台机器的ip地址写入etcd上的列表。confd轮询etcd时查到这台新加入的机器,便会自己把它加进haproxy的backend server里。 这样便实现了负载均衡集群自动化扩容,下线一台nginx机器亦同此理,先调etcd的api删除某台机器,过一分钟在这台nginx上检测不到流量了再把它下线。 扩容过程中没有修改haproxy的配置,也没有部署haproxy。只是调用了etcd的RESTfulAPI,这个风险就比修改haproxy配置文件再部署上线小多了。 4.8 整合基础设施API 所有的公有云厂商都提供了HTTPOpenAPI,包括国外的aws、azure、gce和国内的某公司、某公司、青云。 市场占有率排名靠前的虚拟化软件商也都有HTTPOpenAPI,包括:VMware、Hyper-V、XenServer、OpenStack。 因此技术上有可能把基础设施提供商的API整合进来,实现虚拟机创建、启动、安装操作系统、联网、执行命令、关机、销毁全生命周期的自动化。 和应用部署脚本不同,调用云厂商的API不能由DSL脚本完成,用bash shell来做也非常不方便。应该用PHP、Java之类的应用编程语言写一个应用来做。 至此,虚拟机和操作系统初始化、应用环境部署、应用软件部署全部都实现了自动化,便可以从零创建一台可上线服务的机器。 4.9 跨厂商跨城市故障转移 实现了部署工作代码化和基础设施API整合之后,便可以自由地跨厂商、跨城市迁移:在不同的机房维持两份相同的数据,每分钟同步。当基础设施发生重大故障难以在短时间内恢复时,可以迅速在另外一个有数据的机房将整套应用自动化部署起来。 4.10 弹性伸缩 几乎每一个给人类访问的网站,其服务器资源利用率都是存在明显峰谷的: · 有的尖峰是一年出现一次,典型的例子是阿里的双十一。每年11月11日,电商狂欢。大卖家的进销存系统、淘宝生态链上的SaaS服务商(如在线打印快递单、发送短信券码、物流跟踪)的系统压力也跟着猛涨1-2个数量级。他们投资扩容的硬件设备,只有这一天才能充分利用,平时利用率极低。 · 有的尖峰是一天出现一次或者多次,比如唯品会、聚划算的10点秒杀。基本每一个电商都一天多波次的秒杀、抢购。 · 更普遍的是白天高峰、凌晨到清晨低谷。 自动化运维(包括自动购买分配虚拟机、自动部署应用环境、自动部署应用软件、自动测试)使按需调度计算资源成为了可能。实时的弹性伸缩,意味着每天、甚至每分钟都在做扩容、缩容,这必须要靠自动化运维实现。 4.10.1 公有云上的按需采购 主流的公有云计费粒度都已经细到小时(aws、某公司、某公司),有的做到了按分钟(azure、gce),甚至还有按秒计费的(青云)。 对出现频率较低、计划中的尖峰,人工干预,提前做好扩容和缩容预案,以双十一为例,人工设定好11月10日购买一批按小时计费的机器(不是包年包月),到了11月15日释放这些机器,厂商会停止计费。 对出现频率高的尖峰,运维平台智能调度,比如每5秒采样系统资源利用率,达到指定的扩容阈值就自动买机器并自动化部署、测试、上线服务,低于指定的回收阈值就自动下线服务器、通知厂商停止计费。这种适用于部署上线时间极短的服务,特别是无状态、无用户数据的应用服务器。若需要较长的预热时间(如数据库、缓存、搜索引擎),则需要提前扩容,这就要根据历史性能曲线做智能预测了。 按需购买对公有云厂商也有积极意义: · 从宏观角度讲,用多少买多少,杜绝浪费,提升了全球公有云资源池中的资源利用率,任何提升资源利用率的事情都是有积极正面的。 · 从经济角度讲,公有云按小时售卖的机器单价比包年的贵,如果两种售卖方式都能100%把机器卖出去,按小时计费的总收入更高。 · 目前有的公有云厂商已经出现部分机房物理资源售罄的情况。如果提供实时服务(如电商、支付、新闻、社交)的客户都按需采购,就有可能在闲时把资源释放出来给实时性要求不高的客户(如离线大数据处理、动画渲染)使用。 4.10.2 私有云的业务间调配 已经投资购置大量硬件的企业,可以在不同内部业务之间调度,比如白天把大多数机器用来为消费者提供服务,晚上缩减承担消费者请求的机器规模,释放出来的计算资源用来做大数据处理。 5 自动化运维平台 2012年,我刚在极其艰苦的环境下做了一个自营B2C,恰好看到12306故障频频,觉得自己能带队做一个比他们好的,于是试着去做数据库建模,结果,就是有了《身为码农,为12306说两句公道话》这篇文章,那篇文章太火了,各种微博、微信、论坛累计转发可能有几十万,还登上了《某公司》、《某公司》、《某公司》等10余家平面媒体,连12306的技术负责人(中国铁科院计算所副所长)接受某公司采访都引用我的观点。后来微博上很多人转发说“这兄弟生动地诠释了:你行你上,不行别逼逼”。 2015年,我对运维做了这么多展望,技痒难耐,决定再实践一次“你行你上”,于是我自投资金百万,做了“运维厨房”这样一个自动化运维平台。在这里就不再多做阐述了。 ![]()
| 
 发表于 2017-7-1 10:30
发表于 2017-7-1 10:30



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友