![]()
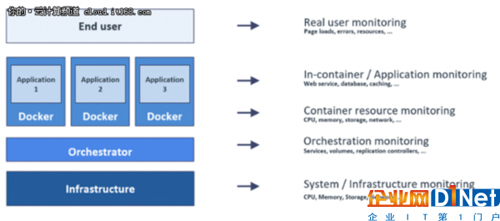
到底什么全栈? “全栈工程师”这个术语在2010年初被提出,表示在整个应用程序堆栈中具有广泛技能的开发人员。包括前端和后端应用程序组件的组合,甚至包括基础设施层的代码体现。使用许多不同的应用程序组件或微服务的容器化应用程序的趋势,增加了现代应用程序堆栈的复杂性。甚至有人批评了“全栈工程师”这个术语。 虽然对于一个人来说,了解应用程序每个部分的开发细节可能是不现实的(除非非常简单),但是应用程序在生产环境中运行时,通常需要堆栈的所有层都具有可见性。这允许开发人员在应用程序或基础设施的适当部分中快速识别问题并采取相应的行动。所以,在这篇文章中,我们回来探索一个容器化应用程序的“全栈”可见性或监视方式。例如,堆栈通常是什么样子的?栈的不同层的相关度量是什么?收集和分析所有这些度量标准需要什么功能? 容器堆栈是什么样的? 在笔者的演示中,经常会使用下面的图片来说明容器化应用程序中最重要的层是什么,并讨论传统的单片应用程序之间的一些重要区别。实际上,随着容器的使用和一些编排平台的使用,还引入了额外的抽象层。现在,从所有这些层收集度量并将它们绑定在一起是非常重要的,能方便我们完全理解一个容器化的应用程序是如何工作的。 ![]()
需要收集哪些指标? 根据上面的图片,为了获得我们的应用程序的全栈可见性,我们需要从下面的层中收集性能指标: ·在基础设施中,我们希望收集不同的资源指标,比如CPU、内存、磁盘、网络等等,可能来自物理服务器或虚拟服务器,也可能是云实例。在后一种情况下,这些指标通常可以通过某种API(如Amazon Cloudwatch)来访问,同样包括我们在云平台上使用的服务的其他指标。 ·通常,一个协调器用于帮助基础设施上的容器的部署、扩展和管理。Kubernetes(或者是Red Hat OpenShift之类的产品)和Docker Swarm是最受欢迎的技术。在这一层,我们希望了解容器计数和容器动态,例如缩放事件。从协调器中,我们还可以收集关于容器如何与服务绑定的服务定义和关系。这允许我们在服务级别进行报告,例如特定服务的容器数量或其他相关指标。 ·对于容器本身,我们还希望了解每个容器和每个服务的资源度量,以及容器生命周期事件。此外,我们希望了解容器内的应用程序是如何运行的。这种所谓的容器监控为我们提供了针对容器内运行的不同服务的应用程序特定的度量标准。 ·最后,我们希望看到对最终用户的影响,并理解作为应用程序的消费者所获得的性能。这通常包括页面加载时间、错误等前端指标,有时甚至可以添加业务指标来“监视真正重要的事情”。 ![]()
其他的考虑 从这些层收集不同的度量标准本身已经是一个挑战。大多数监控工具只关注其中的一个子集,因为它们是为传统的单片应用程序开发的。现代容器监控工具应该与上面提到的所有层进行集成,以提供完整的图像以及防止出现盲点。 但这并不仅仅局限于度量收集。还有一些其他重要的考虑事项,与度量指标和事件的收集方式有关。 ·自动仪表:考虑到容器的短暂特性,新容器在启动时自动监控是至关重要的。这包括认识到已经启动了一个新的容器,以及在内部运行的服务,以及如何监视这些服务。例如,在CoScale中,我们使用一个丰富的插件库来监控来自已知服务的应用程序特定指标,如NGINX、Redis、MongoDB和许多其他服务。 ·另外,当将新节点添加到集群时,重要的是这些节点配置,而且配置了正确的监视代理和设置,这样你的监视就可以与环境进行伸缩。这可以通过在Kubernetes中使用“DaemonSets”的概念或Docker Swarm的全球服务来完成。 ·另一个主要的考虑因素是监视代理运行的位置和它们生成的开销。这是特别相关的,因为容器是轻量级且不可变的结构,应该尽可能少地受到影响。一些监控工具需要将代理添加到容器映像中,或者作为sidecar容器,这通常会增加大量的开销。其他工具,例如CoScale,只需要每个节点上的一个代理(通常是运行它自己的容器),开销增加最小。 ·收集数据是一回事,但理解它则是另一回事。为了获得正确的见解,需要对容器环境进行正确的可视化。一个挤满了所有容器的所有资源指标的图表的仪表盘,并不是很有洞察力。你通常希望从高层次的服务和集群的视图开始,然后在出现问题时能够进行深入的研究。 ·同时,对问题本身的检测也具有挑战性。容器和服务的数量以及它们生成的度量指标的数量已经导致了数据的泛滥。将其与容器的动态方面相结合,你就可以明白为什么经典的报警技术常常会失败。因此,在这样的环境中,更多的自我学习分析技术,例如动态的基底和异常检测,是非常有价值的,并且有助于对问题的主动检测。 ·最后,在发现问题的同时,还应该对它们进行修复。为此,需要收集适当数量的上下文信息来进行故障排除。这包括在问题发生时发生的其他事件的相关性。是否所有的特定服务的容器都受到了影响,或者仅仅是一个?在哪里也有下游服务的问题?更详细的日志数据或跟踪信息可以帮助解决问题服务的故障。 | 
 发表于 2017-7-29 17:18
发表于 2017-7-29 17:18



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友